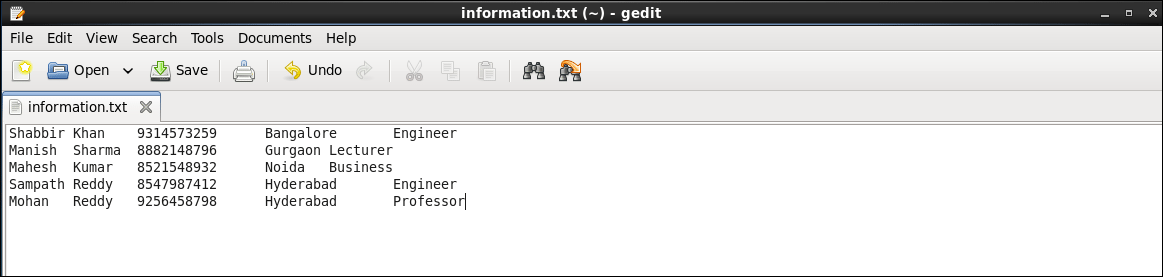
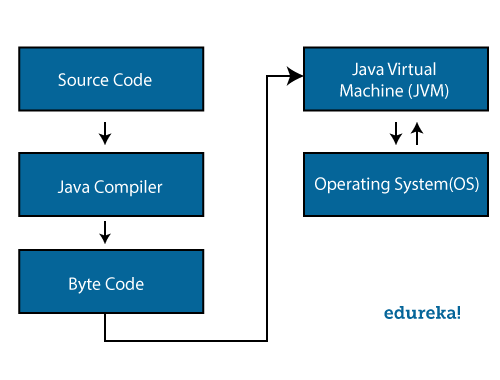
Hadoop-administratoransvar
Denne blog om Hadoop Admin-ansvar diskuterer omfanget af Hadoop-administrationen. Hadoop-administratorjob er i høj efterspørgsel, så lær Hadoop nu!

Denne blog om Hadoop Admin-ansvar diskuterer omfanget af Hadoop-administrationen. Hadoop-administratorjob er i høj efterspørgsel, så lær Hadoop nu!
Apache Spark er kommet op som en stor udvikling inden for databehandling.
Apache Hadoop 2.x består af betydelige forbedringer i forhold til Hadoop 1.x. Denne blog taler om Hadoop 2.0 Cluster Architecture Federation og dens komponenter.
Dette giver et indblik i brugen af Job tracker
Apache Pig har flere foruddefinerede funktioner. Indlægget indeholder klare trin til oprettelse af UDF i Apache Pig. Her er koderne skrevet i Java og kræver svinebibliotek
Der består HBase Storage-arkitektur af adskillige komponenter. Lad os se på funktionerne i disse komponenter og vide, hvordan data skrives.
Apache Hive er en Data Warehousing-pakke bygget oven på Hadoop og bruges til dataanalyse. Hive er målrettet mod brugere, der er fortrolige med SQL.
Implementeringen af Apache Spark med Hadoop i stor skala af topfirmaer indikerer, at det er succes og dets potentiale, når det kommer til realtidsbehandling.
NameNode høj tilgængelighed er en af de vigtigste funktioner i Hadoop 2.0 NameNode høj tilgængelighed med Quorum Journal Manager bruges til at dele redigeringslogfiler mellem Active og Standby NameNodes.
Hadoop-udviklerjobansvaret dækker mange opgaver.Jobansvar afhænger af dit domæne / sektor.Denne rolle ligner en softwareudvikler
Hive-datamodellerne indeholder følgende komponenter som databaser, tabeller, skillevægge og spande eller klynger. Hive understøtter primitive typer som heltal, flyder, dobbelt og strenge.
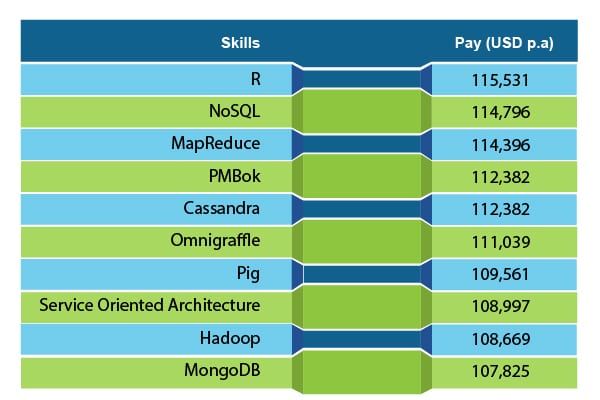
Disse 4 grunde til at opgradere til Hadoop 2.0 taler om Hadoop-jobmarkedet, og hvordan det kan hjælpe dig med at fremskynde din karriere ved at gøre dig åben for enorme jobmuligheder.
I denne blog kører vi eksempler på Hive og Garn på Spark. For det første skal du bygge Hive and Garn on Spark, og så kan du køre Hive and Garn-eksempler på Spark.
Formålet med denne blog er at lære at overføre data fra SQL-databaser til HDFS, hvordan man overfører data fra SQL-databaser til NoSQL-databaser.
Cloudera-certificeret udvikler til Apache Hadoop (CCDH) er et boost til ens karriere. Dette indlæg diskuterer fordelene, eksamensmønstre, studievejledning og nyttige referencer.
Denne blog giver en oversigt over HDFS-arkitekturen med høj tilgængelighed, og hvordan man konfigurerer og konfigurerer en HDFS-klynge med høj tilgængelighed i enkle trin.
Apache Kafka er fortsat populær, når det kommer til realtidsanalyse. Her er et kig på det ud fra et karrieremæssigt synspunkt, der diskuterer karrieremuligheder og jobkrav.
Apache Kafka leverer høj kapacitet og skalerbare meddelelsessystemer, der gør det populært i realtidsanalyse. Lær hvordan en Apache kafka tutorial kan hjælpe dig
Dette blogindlæg er et dybt dyk i svin og dets funktioner. Du finder en demo af, hvordan du kan arbejde på Hadoop ved hjælp af Pig uden afhængighed af Java.
Denne blog diskuterer forudsætninger for at lære Hadoop, Java-essentials til Hadoop & svar 'har du brug for Java for at lære Hadoop', hvis du kender Pig, Hive, HDFS.