Spark vs Hadoop: Hvilken er den bedste Big Data Framework?
Dette blogindlæg taler om apache gnist vs hadoop. Det giver dig en idé om, hvilken ret Big Data-ramme du kan vælge i forskellige scenarier.

Dette blogindlæg taler om apache gnist vs hadoop. Det giver dig en idé om, hvilken ret Big Data-ramme du kan vælge i forskellige scenarier.
Denne blog hjælper dig med at forstå, hvordan du installerer og opsætter sbteclipse-plugin med trinvise instruktioner til kørsel af Scala-applikation i Eclipse IDE.
Dette blogindlæg forklarer, hvorfor du skal komme i gang med Apache Spark efter Hadoop & hvorfor læring af Spark efter mestring af hadoop kan gøre underværker for din karriere!
Denne Apache Drill-tutorial giver dig alle de oplysninger, du har brug for for at komme i gang med Apache Drill-forespørgselsmotor, brug med Hadoop, Big Data & Apache Spark.
Denne Spark Hadoop-blog fortæller dig alt hvad du behøver at vide om Apache Spark combineByKey. Find den gennemsnitlige score pr. Studerende ved hjælp af combineByKey-metoden.
Apache Falcon er en ny datastyringsplatform til Hadoop-økosystemet, der forenkler indbygget foderbehandling og feedadministration på hadoop-klynger. Lær hvordan du konfigurerer det.
Denne Apache Spark-blog forklarer Gnistakkumulatorer i detaljer. Lær brugen af gnistakkumulator med eksempler. Gnistakkumulatorer er som Hadoop Mapreduce-tællere.
Lær alt om Apache Flink & opsætning af en Flink-klynge i denne blog. Flink understøtter realtids- og batchbehandling og er et must-watch Big Data-teknologi til Big Data Analytics.
Dette blogindlæg diskuterer distribueret caching med udsendelsesvariabler og får dig i gang med at distribuere store værdier effektivt i Spark-programmering.
CCA- og CCP-certificeringer fra Cloudera har erstattet CCDH- og CCSHB-eksamen. Denne blog fortæller dig alt hvad du behøver at vide om de nye certificeringer.
Dette blogindlæg diskuterer statefulde transformationer med vindue i Spark Streaming. Lær alt om sporing af data på tværs af batches ved hjælp af state-fulde D-Streams.
Dette blogindlæg diskuterer stateful transformationer i Spark Streaming. Lær alt om kumulativ sporing og dygtighed til en Hadoop Spark-karriere.
Hadoop & Big Data-teknologier revolutionerer sundhedsanalyser. Denne big data i sundhedsbloggen diskuterer, hvordan big data-analyse kan opdrage medicinsk behandling.
Dette blogindlæg på Hadoop Streaming er en trinvis vejledning til at lære at skrive et Hadoop MapReduce-program i Python til at behandle store mængder Big Data.
Denne blog på Big Data Tutorial giver dig et komplet overblik over Big Data, dets egenskaber, applikationer samt udfordringer med Big Data.
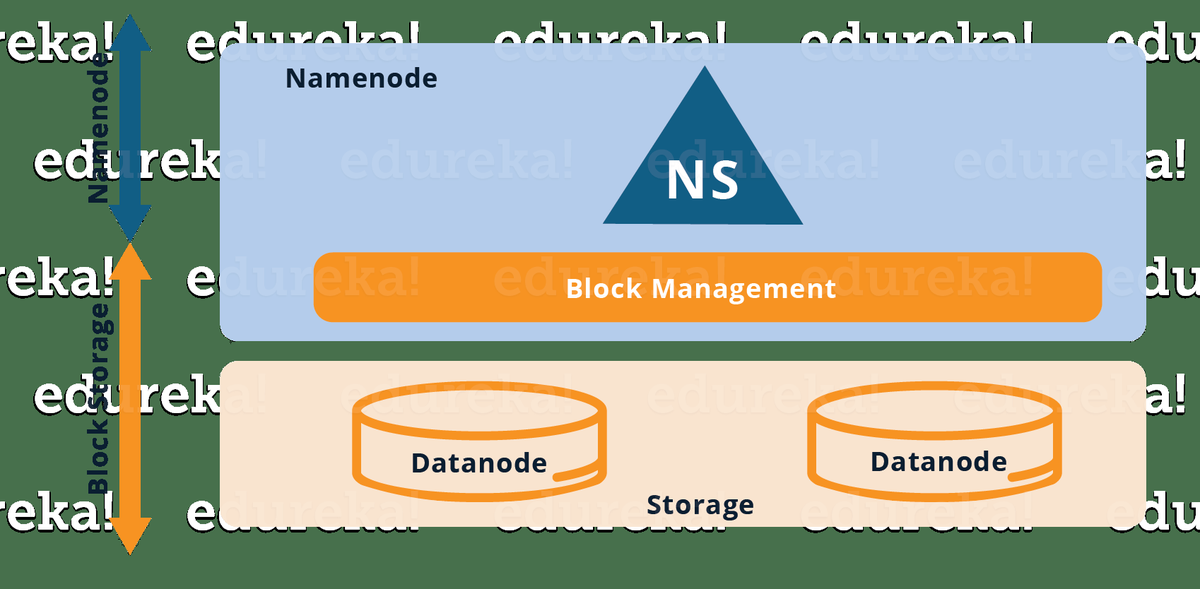
Denne HDFS-selvstudieblog hjælper dig med at forstå HDFS eller Hadoop Distribueret filsystem og dets funktioner. Du vil også kort udforske dets kernekomponenter.
I denne Splunk-selvstudie skal du forstå forskellene mellem Splunk vs. ELK vs. Sumo Logic og afgøre, hvilke af disse værktøjer der passer dig bedst.
I denne Splunk use case-blog vil du forstå, hvordan Domino's Pizza brugte Splunk til at få indsigt i forbrugeradfærd. Og formulere deres forretningsstrategier.
Denne vejledning er en trinvis vejledning til installation af Hadoop-klynge og konfiguration på en enkelt node. Alle Hadoop-installationstrin er til CentOS-maskine.
Denne blog taler om de forskellige HDFS-kommandoer som fsck, copyFromLocal, expunge, cat osv., Som bruges til at styre Hadoop File System.