HBase Tutorial: HBase Introduktion og Facebook Case Study
Denne HBase tutorial blog introducerer dig til, hvad der er HBase & dens funktioner. Den dækker også Facebook Messenger casestudie for at forstå fordelene ved HBase.

Denne HBase tutorial blog introducerer dig til, hvad der er HBase & dens funktioner. Den dækker også Facebook Messenger casestudie for at forstå fordelene ved HBase.
Denne blog er en guide til, hvordan du installerer Puppet Master og Puppet Agent. Det inkluderer også et eksempel på implementering af Apache Tomcat ved hjælp af Puppet Tomcat Module.
Denne blog er en trinvis vejledning til Apache Pig Installation i Linux-miljø. Vi installerer Apache Pig 0.16.0 og kører det i forskellige tilstande.
Denne blog om HBase Architecture forklarer HBase Data Model & giver indsigt i HBase Architecture. Det forklarer også forskellige mekanismer i HBase.
Denne Hive-tutorial-blog giver dig indgående kendskab til Hive Architecture og Hive Data Model. Det forklarer også NASA's casestudie om Apache Hive.
Denne Spark Streaming-blog introducerer dig til Spark Streaming, dens funktioner og komponenter. Det inkluderer et Sentiment Analysis-projekt ved hjælp af Twitter.
Denne Spark MLlib-blog introducerer dig til Apache Sparks Machine Learning-bibliotek. Det inkluderer et filmanbefalingssystemprojekt, der bruger Spark MLlib.
Denne GraphX-selvstudieblog introducerer dig til Apache Spark GraphX, dens funktioner og komponenter inklusive et flydataanalyseprojekt.
Denne Apache Flume tutorial-blog forklarer de grundlæggende aspekter af Apache Flume og dens funktioner. Det viser også Twitter-streaming ved hjælp af Apache Flume.
Apache Sqoop Tutorial: Sqoop er et værktøj til overførsel af data mellem Hadoop og relationsdatabaser. Denne blog dækker import og eksport af Sooop fra MySQL.
Apache Oozie Tutorial: Oozie er et workflow-planlægningssystem til styring af Hadoop-job. Det er et skalerbart, pålideligt og udvideligt system.
Big Data-applikationer revolutionerer organisationer og hjælper dem med at tage mere informative forretningsbeslutninger ved at analysere store datamængder.
Apache Spark har overtaget Big Data & Analytics-verdenen, og Python er et af de mest tilgængelige programmeringssprog, der bruges i branchen i dag. Så her i denne blog lærer vi om Pyspark (gnist med python) for at få det bedste ud af begge verdener.
Denne blog fokuserer på Apache Hadoop YARN, der blev introduceret i Hadoop version 2.0 til ressourcestyring og jobplanlægning. Det forklarer GARN-arkitekturen med dens komponenter og de opgaver, som hver af dem udfører. Den beskriver applikationsindgivelse og workflow i Apache Hadoop YARN.
I denne blog på PySpark Tutorial lærer du om PSpark API, der bruges til at arbejde med Apache Spark ved hjælp af Python Programming Language.
I denne PySpark Dataframe tutorial blog lærer du om transformationer og handlinger i Apache Spark med flere eksempler.
Denne Edureka-blog på Cloudera Hadoop-tutorial giver dig et komplet indblik i forskellige Cloudera-komponenter som Cloudera Manager, pakker, farvetone osv.
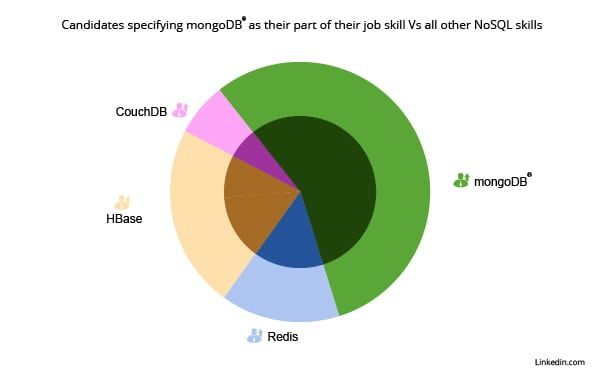
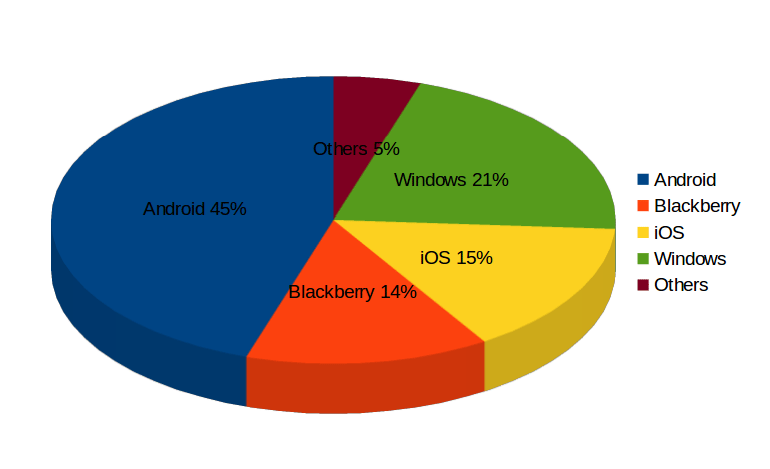
Dette indlæg beskriver om stigningen i efterspørgsel efter Hadoop- og NoSQL-færdigheder inden for IT og andre områder. læs videre for at se, hvordan Hadoop og NoSQL-færdigheder vil hjælpe
Denne blog diskuterer fordelene ved Hadoop-implementering, Hadoop-initiativer, Hadoop i små og store organisationer og karrierefordele ved Hadoop-træning.
Hadoop er blevet en varm færdighed, der skal erhverves i IT-kredsløbet, antallet af Hadoop-elevers profil stiger drastisk dag for dag.